LOMBA ARTIKEL ILMIAH NASIONAL
LINGFEST 2023
PREDIKSI DINI PENYAKIT DIABETES UNTUK GENERASI MUDA YANG SEHAT PADA ERA SOCIETY 5.0 MENGGUNAKAN ALGORITMA ARTIFICIAL NEURAL NETWORK (ANN)

Disusun Oleh:
Universitas Sebelas Maret
1. Hafidh Muhammad Akbar
2. Afif Nur Fauzi
3. Alfiki Diastama Afan Firdaus
PROGRAM STUDI INFORMATIKA
UNIVERSITAS SEBELAS MARET
2023
Abstrak
Diabetes adalah penyakit kronis akibat gangguan metabolisme yang ditandai dengan peningkatan kadar glukosa darah. Penyakit ini dapat menimbulkan penyakit-penyakit kronis lainnya, seperti kerusakan serius pada jantung, pembuluh darah, mata, ginjal, dan saraf. Menurut data dari Ikatan Dokter Anak Indonesia (IDAI), data anak yang menderita diabetes mengalami peningkatan sebanyak 70 kali lipat pada bulan Januari 2023 dibandingkan dengan tahun 2010. Angka ini tergolong tinggi dan dapat meningkat tanpa disadari dan tanpa pencegahan oleh penderitanya. Mengingat konsekuensi serius yang ditimbulkan dari penyakit ini, prediksi dini perlu dibuat untuk meningkatkan pencegahan diabetes pada generasi muda di era Society 5.0. Penelitian ini bertujuan untuk membuat sistem deteksi dini penyakit diabetes dengan mengikuti tahapan CRISP-DM dan algoritma Artificial Neural Network (ANN) Backpropagation. Dataset yang digunakan bersumber dari Rekam Medis Elektronik (Electronic Health Records (EHRs) yang disediakan oleh Kaggle. Dataset tersebut akan dibagi menjadi data training sebanyak 80% dan data testing sebanyak 20%. Model yang dihasilkan dalam penelitian ini memiliki tingkat akurasi sebesar 96%. Dengan prediksi ini, pencegahan diabetes pada generasi muda di era Society 5.0 dapat ditingkatkan.
Kata kunci: Diabetes, Artificial Neural Network, Backpropagation
1. Pendahuluan
Di era modern, generasi muda memiliki peran penting dalam memajukan masyarakat menuju Era Society 5.0. Era ini ditandai oleh pemanfaatan teknologi yang berbasis pada kecerdasan buatan (artificial intelligence), Internet of Things, dan perkembangan digital yang lain. Kreativitas dan inovasi menjadi kunci utama. Generasi muda yang kreatif dan inovatif, didukung dengan tekad yang kuat, akan menjadi penggerak utama dalam menciptakan solusi baru atas permasalahan yang muncul di Era ini.
Menjaga kesehatan generasi muda menjadi hal yang krusial dalam mewujudkan visi optimalisasi generasi muda di Era Society 5.0. Kesehatan yang baik memberikan kesempatan bagi generasi muda untuk berkembang secara optimal. Dengan menjaga kesehatan, generasi muda dapat menghadapi tantangan dan mengonversinya menjadi peluang untuk menciptakan solusi dengan lebih baik.
Namun, ada masalah baru di era ini, tantangan dalam menjaga kesehatan generasi muda semakin kompleks. Salah satu masalah adalah ancaman diabetes yang meningkat drastis pada generasi muda ini. Data terbaru laporan dari BBC pada tanggal 6 Februari 2023, Ikatan Dokter Anak Indonesia (IDAI) telah merilis data yang mengungkapkan bahwa jumlah anak yang
2
menderita diabetes mengalami peningkatan sebanyak 70 kali lipat pada bulan Januari 2023 dibandingkan dengan tahun 2010.
Kenaikan 70 kali lipat bukanlah angka yang kecil. Tindakan preventif dan pengelolaan kesehatan yang lebih baik di kalangan generasi muda sangat diperlukan. Melalui prediksi dini penyakit diabetes, teknologi kecerdasan buatan (AI) dapat digunakan sebagai tindakan preventif terhadap penyakit diabetes. Dengan prediksi lebih awal, pencegahan penyakit diabetes pada generasi muda, yang memiliki risiko lebih tinggi, dapat dilakukan secara efektif dan efisien.
Oleh karena itu, penulis memanfaatkan teknologi AI, khususnya algoritma Artificial Neural Network (ANN), untuk memprediksi penyakit diabetes. ANN dapat mengidentifikasi pola serta hubungan yang kompleks antara variabel-variabel yang berkontribusi terhadap diabetes. Hal ini memungkinkan kita untuk mengenali risiko diabetes pada generasi muda dengan lebih akurat dan memberikan langkah-langkah pencegahan yang tepat dan efisien.
Dengan menerapkan teknologi ANN untuk memprediksi penyakit diabetes, diharapkan generasi muda dapat lebih memahami risiko yang mereka hadapi dan mengambil langkah-langkah pencegahan yang diperlukan. Pendekatan ini diharapkan dapat memastikan kesehatan optimal generasi muda dan memberi mereka kesempatan terbaik untuk berpartisipasi dalam perkembangan kreativitas, inovasi, dan teknologi di Era Society 5.0.
2. Metode Penelitian
Gambar 1. Metode Penelitian
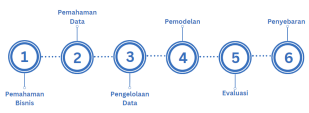
Terdapat beberapa tahapan atau fase yang harus dilakukan di dalam pengembangan sistem ini. Tahapan yang dilakukan akan mengikuti tahapan CRISP-DM (Standard Process for Data Mining). Menurut Wiratama M. A. dkk., (2022), CRISP-DM adalah salah satu model atau framework yang digunakan di dalam pengembangan data mining yang memiliki enam tahapan dan masing-masing tahapan sangat bergantung dengan hasil yang didapatkan pada tahapan sebelumnya.
3
Menurut Wiratama M. A. dkk., (2022), dalam tahapan CRISP-DM, terdapat enam tahapan, yaitu meliputi sebagai berikut:
2.1. Tahapan pemahaman bisnis (Business Understanding)
Tahap awal yang dilakukan penulis dalam melakukan penelitian adalah menentukan tujuan dari permasalahan atau hambatan yang akan dipecahkan atau diatasi di Era Society 5.0.
2.2. Tahapan pemahaman data (Data Understanding)
Tahap selanjutnya penulis akan mengumpulkan data-data yang diperlukan dalam pembuatan sistem serta menganalisis data. Di dalam penelitian ini, data yang digunakan adalah dataset yang disediakan oleh website kaggle.com.
2.3. Tahapan pengelolaan data (Data Preparation)
Setelah diperoleh data-data yang diperlukan, langkah selanjutnya adalah mengolah atau menyiapkan data awal. Dataset yang digunakan terdiri dari 9 atribut, meliputi gender, age, hypertension, hearth_disease, smoking_history, HbA1c_level, blood_glucose, dan diabetes. Selain itu, pada tahapan ini dilakukan filtering data, misalnya penghapusan data duplikat atau data yang bersifat null.
2.4. Tahapan pemodelan (Modeling)
Pada tahapan ini, akan dipilih jenis model yang akan digunakan dalam proses training data, yaitu menggunakan algoritma Artificial Neural Network (ANN).
2.5. Tahapan Evaluasi (Evaluation)
Setelah model berhasil dibentuk, maka selanjutnya akan dilakukan analisis apakah model memenuhi tujuan atau tidak dengan cara melihat akurasi yang didapatkan dari proses testing.
2.6. Tahapan penyebaran (Deployment)
Tahapan ini merupakan tahapan terakhir dalam siklus CRISP DM. Pada tahap ini, akan dilakukan pembuatan laporan dan atau jurnal ilmiah.
3. Pembahasan
Diabetes adalah penyakit kronis yang terjadi akibat gangguan metabolisme, ditandai dengan peningkatan kadar glukosa darah (atau gula darah). Secara bertahap, kondisi ini dapat menyebabkan kerusakan serius pada jantung, pembuluh darah, mata, ginjal, dan saraf (WHO, 2023).
Penelitian yang dikutip dalam studi ini, yang dilakukan oleh Azhar, dkk., (2022), telah mengungkapkan hubungan yang signifikan antara faktor-
4
faktor tertentu dengan risiko terjadinya diabetes. Faktor-faktor tersebut antara lain hipertensi, riwayat merokok, BMI, dan level HbA1c. Selain itu, umur dan jenis kelamin juga mempengaruhi penyakit diabetes. Menurut Gunawan, dkk., (2021). Dalam hal ini, perempuan cenderung memiliki risiko yang lebih tinggi untuk terkena penyakit diabetes.
Faktor-faktor selain yang disebutkan di atas ditunjukkan oleh Barrett Connor, dkk. (2018) yaitu penyakit jantung. Penyakit jantung menjadi penyebab utama morbiditas dan mortalitas pada diabetes.
Penelitian ini dilakukan dengan mencari dataset dari website kaggle.com, yang biasa digunakan sebagai website berbagi dataset. Dataset yang dipilih telah memenuhi skor Usability 10.0 dan memiliki skor kredibilitas 100% berdasarkan informasi dari Kaggle. Sumber data berasal dari Rekam Medis Elektronik (Electronic Health Records atau EHRs). EHRs adalah versi digital dari catatan kesehatan pasien yang berisi informasi tentang riwayat medis, diagnosis, pengobatan, dan hasil. Data dalam EHRs dikumpulkan dan disimpan oleh penyedia layanan kesehatan, seperti rumah sakit dan klinik, sebagai bagian dari praktik klinis rutin mereka.
Dataset ini mempunyai 100000 baris dan 9 atribut, di antaranya adalah: gender, age, hypertension, heart_disease, smoking_history, bmi, HbA1c_level, blood_glucose_level, dan diabetes (sebagai outcome). Isi atribut dapat dilihat pada gambar di bawah.
Gambar 2. Dataset awal

Dari gambar di atas, dataset memiliki total 9 variabel yang terdiri dari 8 variabel independen dan 1 variabel dependen. Tabel 1 dan tabel 2 berikut menjelaskan detail dari setiap variabel tersebut, baik variabel dependen (Y) dan variabel independen (X).
Tabel 1. Variabel independen (X)
5
6
Tabel 2 Variabel dependen (Y)
Penulis kemudian melakukan langkah-langkah preprocessing data untuk memastikan data dapat digunakan dengan tepat saat proses klasifikasi. Tahapan ini dimulai dengan melakukan pembersihan data (data cleaning) untuk memeriksa apakah ada nilai null (missing value) dan data duplikat dalam data yang digunakan. Jika ada data null, langkah selanjutnya adalah menghapus baris dari data yang memiliki nilai null. Jika terdapat data duplikat, data pertama akan dipertahankan, kemudian data duplikasinya akan dihapus, sehingga semua nilai data akan unik. Setelah dilakukan cleaning data, baris dari dataset menjadi 96146 baris.
Selanjutnya, data dipisahkan menjadi variabel x dan y, dan dilakukan splitting data. Setelah melakukan splitting data, penulis melakukan Feature Scaling untuk menyamaratakan skala dari nilai data yang digunakan.
Setelah dilakukan splitting data dan scaling data, langkah selanjutnya adalah memodelkan data menggunakan algoritma ANN (Artificial Neural Network) dengan Backpropagation. Proses training model akan menggunakan parameter jumlah epoch 800, learning rate 0.001.
Backpropagation adalah inti dari pelatihan jaringan saraf. Metode ini dipakai untuk menyempurnakan bobot jaringan saraf berdasarkan tingkat kesalahan yang diperoleh pada epoch (iterasi) sebelumnya. Penyesuaian bobot yang tepat memungkinkan pengurangan tingkat kesalahan dan membuat model dapat diandalkan dengan meningkatkan generalisasinya.
7
Algoritma backpropagation bekerja dengan cara sebagai berikut. (Purnomo & Kurniawan, 2006).
Gambar 3. Cara kerja algoritma backpropagation
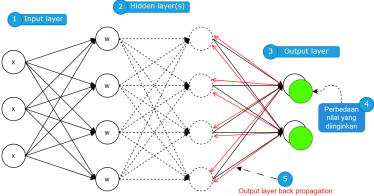
1. Input X, tiba melalui jalur yang telah terhubung sebelumnya 2. Input dimodelkan menggunakan bobot nyata W. Bobot biasanya dipilih secara acak.
3. Hitung output untuk setiap neuron dari lapisan input, ke lapisan tersembunyi, lalu ke lapisan output.
4. Hitung kesalahan dalam output
�������� = ������������ ������������ – ������������ �������� ��������������������
5. Lakukan perjalanan kembali dari lapisan keluaran ke lapisan tersembunyi untuk menyesuaikan bobot sedemikian rupa sehingga kesalahan berkurang. Model dari arsitektur Neural Network yang akan dibuat terdiri dari delapan input layer, lima belas hidden layer, dan 1 output layer dan menggunakan urutan lapisan yang berurutan (sekuensial). Dalam pembuatan algoritma ini, sebelumnya penulis menambahkan lapisan dense ke dalam model ANN. Lapisan dense adalah lapisan yang terhubung penuh secara densely (sepenuhnya) ke lapisan sebelumnya.
8

Gambar 4. Model ANN yang dibuat
Fungsi aktivasi yang akan digunakan terdiri dari dua jenis, yaitu fungsi aktivasi ReLU (Rectified Linear Unit) dan Sigmoid. Menurut Szandała, T., (2021), fungsi ReLU merupakan fungsi aktivasi yang digunakan di dalam input layer dan hidden layer serta berfungsi untuk memetakan angka apa pun ke nol jika negatif, dan sebaliknya memetakannya ke dirinya sendiri. Fungsi ReLU didapatkan dari rumus berikut.
��(��) = ������(0, ��)
(Szandała, 2021) Fungsi sigmoid adalah fungsi yang digunakan di dalam output layer dan berfungsi untuk memetakan angka apa pun antara 0 dan 1, termasuk ke dirinya sendiri. (Sharma, 2020). Fungsi sigmoid untuk target output binary didapatkan dari rumus berikut.
��(��) =1
1 + ��−��
Untuk menghitung tingkat akurasi dari model yang telah dibuat, akan digunakan parameter confusion matrix yang pada dasarnya akan memberikan informasi perbandingan hasil yang didapatkan oleh model dengan hasil pada data sesungguhnya.
9
Berdasarkan hasil dari gambar di atas, hasil akurasi yang didapatkan adalah sebesar 96%, dengan jumlah prediksi benar 11.646 dari total data testing sebanyak 12.619. Nilai akurasi tersebut didapatkan dari perhitungan: �������������� =����������ℎ �������������� ����������
���������� �������� �������������� �������� ���������� × 100%
4. Kesimpulan
Dalam penelitian ini, penulis berhasil mengembangkan pendekatan prediksi dini penyakit diabetes menggunakan algoritma Artificial Neural Network (ANN) untuk menjaga kesehatan generasi muda dalam era Society 5.0.
Penulis telah melakukan pengujian model ANN dengan data testing dan menghasilkan tingkat akurasi sebesar 96%. Dengan hasil tersebut, dapat disimpulkan bahwa model yang dibuat dapat memberikan prediksi risiko diabetes dengan cepat dan akurat.
Penelitian ini diharapkan dapat mengurangi kemungkinan terjadinya diabetes. Hal ini akan berkontribusi pada kualitas hidup dan kesehatan generasi muda di era Society 5.0. Untuk meningkatkan efektivitas pendekatan ini, penelitian selanjutnya diharapkan dapat memperluas cakupan data yang dipakai, dan mengoptimalkan model ANN dengan teknik yang lebih baik.
5. Daftar Pustaka
Azhar, S., Khan, F. Z., Khan, S. T., & Iftikhar, B. (2022). Raised Glycated Hemoglobin (HbA1c) Level as a Risk Factor for Myocardial Infarction in Diabetic Patients: A Hospital-Based, Cross-Sectional Study in Peshawar. Cureus, 14(6), e25723. https://doi.org/10.7759/cureus.25723.
Barrett-Connor E, Wingard D, Wong N, et al. (2018). Heart Disease and Diabetes. dari: Cowie CC, Casagrande SS, Menke A, et al., editors. Diabetes in America. 3rd edition. Bethesda (MD): National Institute of Diabetes and Digestive and Kidney Diseases (US).
BBC News Indonesia. (2023, Februari 6). Kasus diabetes anak meningkat 70 kali lipat ‘sangat mengkhawatirkan’, imbas makanan-minuman manis ‘mudah dijangkau’ di tengah regulasi yang ‘belum cukup melindungi’. Diakses pada 30 Mei 2023, dari https://www.bbc.com/indonesia/articles/clj6rene4y7o.
Dave, A., & Pandi, G.S. (2018). Analysis Of Heart Disease Prediction System Using Artificial Neural Network. Journal of emerging technologies and innovative research.
10
Edgardo Olvera Lopez, Brian D. Ballard, Arif Jan. (2022). Cardiovascular Disease. StatPearls Publishing: 2023
Gunawan, S., & Rahmawati, R. (2021). Hubungan Usia, Jenis Kelamin dan Hipertensi dengan Kejadian Diabetes Mellitus Tipe 2 di Puskesmas Tugu Kecamatan Cimanggis Kota Depok Tahun 2019. Arsip Kesehatan Masyarakat, 6(1), 15-22.
Hall, D. M., & Cole, T. J. (2006). What use is the BMI?. Archives of disease in childhood, 91(4), 283-286.
Hovi, H. S. W., Hadiana, A. I., & Umbara, F. R. (2022). Prediksi Penyakit Diabetes Menggunakan Algoritma Support Vector Machine (SVM). Informatics and Digital Expert (INDEX), 4(1), 40-45.
Little, R. R., & Sacks, D. B. (2009). HbA1c: how do we measure it and what does it mean?. Current Opinion in Endocrinology, Diabetes and Obesity, 16(2), 113-118.
Purnomo, M. H., & Kurniawan, A. (2006). Supervised Neural Network dan Aplikasinya. Yogyakarta: Graha Ilmu.
Rifai, B. (2013). Algoritma Neural Network Untuk Prediksi Penyakit Jantung. Techno Nusa Mandiri, 10(1), 1-9.
Szandała, T. (2021). Review and comparison of commonly used activation functions for deep neural networks. Bio-inspired neurocomputing, 203- 224.
Sharma, S., Sharma, S., & Athaiya, A. (2017). Activation functions in neural networks. Towards Data Sci, 6(12), 310-316.
Staessen, J. A., Wang, J., Bianchi, G., & Birkenhäger, W. H. (2003). Essential hypertension. The Lancet, 361(9369), 1629-1641.
WHO, W. (2023). Diabetes. https://www.who.int/health-topics/diabetes, diakses pada 5 Juni 2023
Wiratama, M. A., & Pradnya, W. M. (2022). Optimasi algoritma data mining menggunakan backward elimination untuk klasifikasi penyakit diabetes. Jurnal Nasional Pendidikan Teknik Informatika: JANAPATI, 11(1).
Witjaksana, E. C. P., Saedudin, R. R., & Widartha, V. P. (2021). Perbandingan Akurasi Algoritma Random Forest Dan Algoritma Artificial Neural Network Untuk Klasifikasi Penyakit Diabetes. eProceedings of Engineering, 8(5).


0 comments:
Posting Komentar